
Trino Connector for Azure Data Factory (Pipeline)
Trino Connector empowers you to query diverse Trino data sources to perform comprehensive analytics effortlessly.
In this article you will learn how to quickly and efficiently integrate Trino data in Azure Data Factory (Pipeline) without coding. We will use high-performance Trino Connector to easily connect to Trino and then access the data inside Azure Data Factory (Pipeline).
Let's follow the steps below to see how we can accomplish that!
Trino Connector for Azure Data Factory (Pipeline) is based on ZappySys JDBC Bridge Driver which is part of ODBC PowerPack. It is a collection of high-performance ODBC drivers that enable you to integrate data in SQL Server, SSIS, a programming language, or any other ODBC-compatible application. ODBC PowerPack supports various file formats, sources and destinations, including REST/SOAP API, SFTP/FTP, storage services, and plain files, to mention a few.
Prerequisites
Before we begin, make sure you meet the following prerequisite:
-
Java 11 Runtime Environment (JRE) installed. It is recommended to use these distributions:
Download Trino JDBC driver
To connect to Trino in Azure Data Factory (Pipeline), you will have to download JDBC driver for it, which we will use in later steps. Let's perform these little steps right away:
- Visit Trino official website.
-
Download the JDBC driver, and save it locally,
e.g. to
D:\Drivers\JDBC\trino-jdbc.jar. - Done! That was easy, wasn't it? Let's proceed to the next step.
Create ODBC Data Source (DSN) based on ZappySys JDBC Bridge Driver
Step-by-step instructions
To get data from Trino using Azure Data Factory (Pipeline) we first need to create a DSN (Data Source) which will access data from Trino. We will later be able to read data using Azure Data Factory (Pipeline). Perform these steps:
-
Download and install ODBC PowerPack.
-
Open ODBC Data Sources (x64):

-
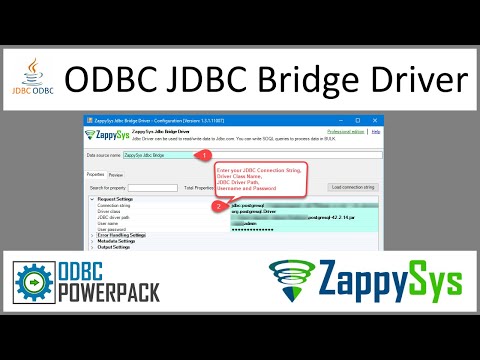
Create a User data source (User DSN) based on ZappySys JDBC Bridge Driver
ZappySys JDBC Bridge Driver
-
Create and use User DSN
if the client application is run under a User Account.
This is an ideal option
in design-time , when developing a solution, e.g. in Visual Studio 2019. Use it for both type of applications - 64-bit and 32-bit. -
Create and use System DSN
if the client application is launched under a System Account, e.g. as a Windows Service.
Usually, this is an ideal option to use
in a production environment . Use ODBC Data Source Administrator (32-bit), instead of 64-bit version, if Windows Service is a 32-bit application.
Azure Data Factory (Pipeline) uses a Service Account, when a solution is deployed to production environment, therefore for production environment you have to create and use a System DSN. -
Create and use User DSN
if the client application is run under a User Account.
This is an ideal option
-
Now, we need to configure the JDBC connection in the new ODBC data source. Simply enter the Connection string, credentials, configure other settings, and then click Test Connection button to test the connection:
TrinoDSNjdbc:trino://trino-instance-host-name:8080D:\Drivers\JDBC\trino-jdbc.jaradmin****************[]
Use these values when setting parameters:
-
Connection string :jdbc:trino://trino-instance-host-name:8080 -
JDBC driver file(s) :D:\Drivers\JDBC\trino-jdbc.jar -
User name :admin -
User password :**************** -
Connection parameters :[]
-
-
You should see a message saying that connection test is successful:

Otherwise, if you are getting an error, check out our Community for troubleshooting tips.
-
We are at the point where we can preview a SQL query. For more SQL query examples visit JDBC Bridge documentation:
TrinoDSNSELECT * FROM tpch.sf1.orders
SELECT * FROM tpch.sf1.ordersYou can also click on the <Select Table> dropdown and select a table from the list.The ZappySys JDBC Bridge Driver acts as a transparent intermediary, passing SQL queries directly to the Trino JDBC driver, which then handles the query execution. This means the Bridge Driver simply relays the SQL query without altering it.
Some JDBC drivers don't support
INSERT/UPDATE/DELETEstatements, so you may get an error saying "action is not supported" or a similar one. Please, be aware, this is not the limitation of ZappySys JDBC Bridge Driver, but is a limitation of the specific JDBC driver you are using. -
Click OK to finish creating the data source.
Video Tutorial
Read data in Azure Data Factory (ADF) from ODBC datasource (Trino)
-
To start press New button:

-
Select "Azure, Self-Hosted" option:

-
Select "Self-Hosted" option:

-
Set a name, we will use "OnPremisesRuntime":

-
Download and install Microsoft Integration Runtime.
-
Launch Integration Runtime and copy/paste Authentication Key from Integration Runtime configuration in Azure Portal:

-
After finishing registering the Integration Runtime node, you should see a similar view:

-
Go back to Azure Portal and finish adding new Integration Runtime. You should see it was successfully added:

-
Go to Linked services section and create a new Linked service based on ODBC:

-
Select "ODBC" service:

-
Configure new ODBC service. Use the same DSN name we used in the previous step and copy it to Connection string box:
TrinoDSNDSN=TrinoDSN
-
For created ODBC service create ODBC-based dataset:

-
Go to your pipeline and add Copy data connector into the flow. In Source section use OdbcDataset we created as a source dataset:

-
Then go to Sink section and select a destination/sink dataset. In this example we use precreated AzureBlobStorageDataset which saves data into an Azure Blob:

-
Finally, run the pipeline and see data being transferred from OdbcDataset to your destination dataset:

Conclusion
In this article we showed you how to connect to Trino in Azure Data Factory (Pipeline) and integrate data without any coding, saving you time and effort. It's worth noting that ZappySys JDBC Bridge Driver allows you to connect not only to Trino, but to any Java application that supports JDBC (just use a different JDBC driver and configure it appropriately).
We encourage you to download Trino Connector for Azure Data Factory (Pipeline) and see how easy it is to use it for yourself or your team.
If you have any questions, feel free to contact ZappySys support team. You can also open a live chat immediately by clicking on the chat icon below.
Download Trino Connector for Azure Data Factory (Pipeline) Documentation


 Connector")



















 Connector")



 Connector")





























